RAG as the New Knowledge Operating System
Most organizations don’t have a data problem. They have a thinking problem. Information exists everywhere — documents, dashboards, tools, emails, portals. Yet when leaders ask simple questions, answers take days. And when answers arrive, they often lack context, confidence, or clarity. Over the last few years, many teams tried solving this with better search, better dashboards, or smarter chatbots. What we saw instead was fragmentation. This is where Retrieval-Augmented Generation (RAG) quietly changes the conversation. Not as another AI feature. But as something closer to a Knowledge Operating System — a layer that sits above tools, data, and documents, and focuses on how knowledge flows to decisions.
12/26/20257 min read


The Real Knowledge Problem Inside Organizations
In most organizations, knowledge already exists.
It lives in strategy decks.
In operating procedures.
In emails, tickets, CRM notes, policy documents, dashboards, and shared drives.
Yet when leaders or teams ask questions like:
“What is the current status, and why?”
“What changed since last quarter?”
“What should we do next, given our constraints?”
The answers don’t surface easily.
What we consistently see is this:
People search, but don’t get clarity
Teams prepare, instead of answering
Decisions are delayed, not because data is missing, but because context is scattered
Most systems are built to store information.
Very few are built to support thinking.
That gap grows wider as organizations scale.
More tools are added.
More documents are created.
More dashboards are built.
But knowledge becomes harder to use, not easier.
This is the problem RAG starts to solve — not by adding another interface, but by rethinking how knowledge flows to decisions.
What RAG Really Is (In Simple Terms)
RAG stands for Retrieval-Augmented Generation.
But the name often makes it sound more complex than it is.
At a simple level, RAG does three things in sequence:
Retrieves the most relevant knowledge
Frames it with context
Generates an answer that can be used
What matters is not the technology itself, but the behavior it enables.
In traditional systems:
Search gives you links
Dashboards give you metrics
Documents give you content
RAG gives you reasoned answers.
Not guesses.
Not summaries stitched together blindly.
But answers formed by reasoning over trusted knowledge.
This is also why RAG should not be confused with a chatbot.
A chatbot talks.
RAG thinks with your knowledge.
When done well, it behaves less like a conversation tool and more like a decision support layer that understands:
What the question is really asking
Which knowledge matters
What context must be applied before responding
This distinction is critical.
Because once RAG starts operating this way, it naturally moves beyond being “an AI feature” and begins to act like something foundational.
Why RAG Behaves Like a Knowledge Operating System
To understand this shift, it helps to think about what an operating system actually does.
An operating system doesn’t just store files.
It decides:
What gets accessed
In what order
Under what rules
And for which purpose
It orchestrates complexity so humans can focus on outcomes.
This is exactly how RAG starts behaving when implemented well.
Instead of asking people to:
Find documents
Interpret multiple sources
Reconcile versions
Apply context manually
RAG begins to coordinate knowledge behind the scenes.
From what we’ve seen in practice, strong RAG systems naturally develop four OS-like traits:
1. Control
Not all knowledge is equal.
RAG systems enforce which sources matter for which questions.
2. Context Awareness
The same question asked by a CXO, a manager, or an operator should not yield the same answer.
RAG applies role, timing, and intent before responding.
3. Repeatability
Answers are not one-off conversations.
They follow consistent reasoning paths that teams can trust.
4. Learning Loops
Over time, the system improves by observing:
Which answers helped decisions
Which ones caused confusion
Where knowledge needs refinement
At this point, RAG stops being “AI on top of documents.”
It becomes a knowledge control layer — one that sits above tools, systems, and repositories, quietly shaping how decisions get made.
And this is why calling it a Knowledge Operating System is not a metaphor.
It is a functional description.
How This Looks in the Real World
When RAG is treated as a Knowledge Operating System, the change is subtle but powerful.
It doesn’t announce itself loudly.
It simply removes friction from everyday thinking.
Based on what has worked well across clients, we’ve seen patterns like these emerge:
Leaders stop preparing excessive decks just to get answers.
They ask questions directly and receive responses grounded in current, trusted knowledge.
Operations teams no longer jump between systems to understand what went wrong.
They get explanations that connect events, policies, and past actions into a single view.
Support teams move beyond scripts.
They respond with confidence because answers are aligned with the latest product, policy, and operational context.
Strategy and transformation teams align faster.
Everyone reasons from the same base of knowledge, not from personal interpretations of documents.
What’s important here is not speed alone.
It’s confidence.
People trust the answers because they know:
Where the knowledge came from
Why it was used
How the context was applied
That trust is what allows RAG to move from experimentation into everyday use.
And once that happens, organizations stop asking,
“Can AI answer this?”
They start asking,
“Why don’t we already know this?”
How We Approach Building a RAG-Based Knowledge OS
(High-level, step by step — based on what has worked)
This is where many teams expect complexity.
In reality, the most successful implementations start with discipline, not technology.
Below is the high-level approach that has worked consistently.
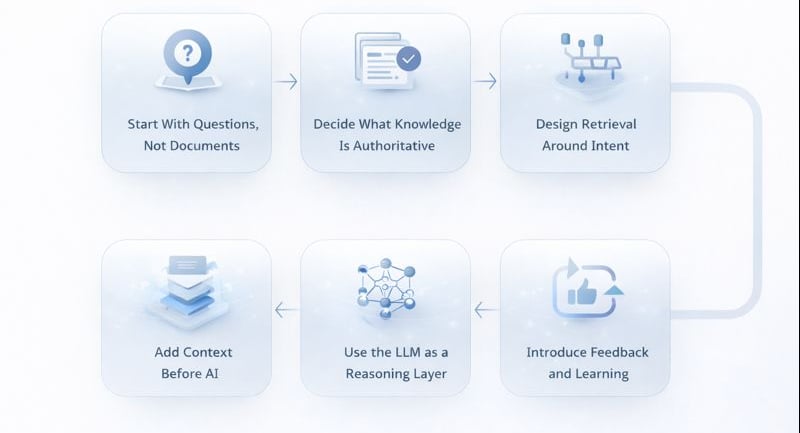
Step 1: Start With Questions, Not Documents
Most RAG initiatives fail before they begin because they start by indexing everything.
What works better is the opposite.
We begin by identifying:
Questions leaders ask repeatedly
Questions teams struggle to answer quickly
Questions that influence decisions, not curiosity
This immediately creates focus.
Instead of asking,
“What documents do we have?”
The system is shaped around,
“What must the organization be able to answer confidently?”
Step 2: Decide What Knowledge Is Authoritative
Not all knowledge deserves equal trust.
In practice, strong Knowledge OS designs:
Clearly mark which sources are authoritative
Assign ownership to knowledge domains
Avoid blending drafts, opinions, and policies
This step is less about AI and more about governance.
Without it, answers may sound fluent but fail to earn trust.
Step 3: Design Retrieval Around Intent, Not Keywords
Keyword search assumes people know what to look for.
In reality, they often don’t.
RAG systems that work well retrieve knowledge based on:
The intent of the question
The role of the person asking
The situation in which the question is asked
This is where retrieval becomes thinking support, not lookup.
Step 4: Add Context Before AI
This is one of the most important steps.
Before generation ever happens, context is applied:
Timeframe
Business rules
Policies
Scope and constraints
When this step is skipped, AI appears intelligent but behaves inconsistently.
When done well, answers feel grounded and relevant.
Step 5: Use the LLM as a Reasoning Layer
Here, the model is not a knowledge source.
It is a reasoning engine.
Connects retrieved knowledge
Applies context
Forms explanations and recommendations
This distinction prevents hallucination and builds confidence in outputs.
Step 6: Introduce Feedback and Learning
Effective Knowledge OS designs capture signals like:
Was the answer useful?
Did it require follow-up?
Was clarification needed?
These signals improve:
Retrieval quality
Context rules
Knowledge curation
Learning happens without rebuilding the system.
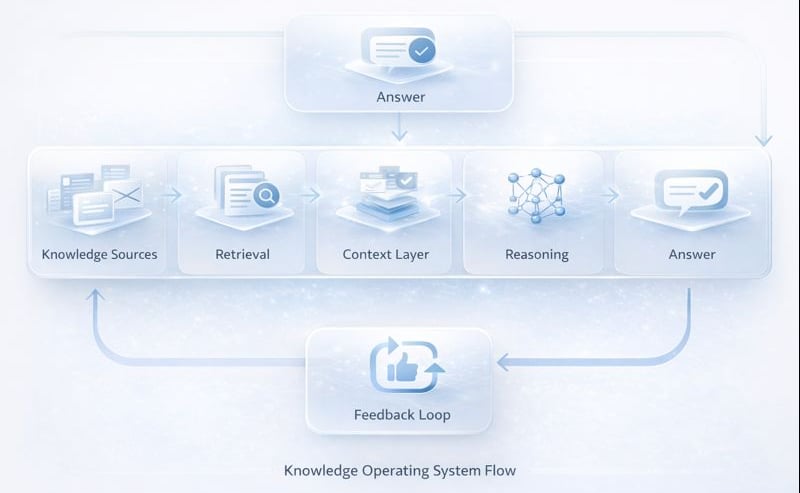
How a Knowledge Operating System Actually Flows
This diagram represents the simplest way to understand a RAG-based Knowledge Operating System.
It is not a technology diagram.
It is a thinking diagram.
Here’s how to read it.
Knowledge Sources
These are not “all documents.”
They are curated, authoritative knowledge sources — policies, operating procedures, structured data, and trusted content that the organization stands behind.
Retrieval Layer
This layer decides what to pull for a given question.
Not based on keywords alone, but on relevance, intent, and trust.
Context Layer
This is the most underestimated part of the system.
It applies:
Role
Time
Business rules
Scope and constraints
Before any reasoning happens.
Reasoning Layer (LLM)
The model does not invent answers.
It reasons over retrieved knowledge within the provided context.
This is where explanations form, trade-offs are articulated, and recommendations become usable.
Answer Layer
What comes out is not raw information.
It is a decision-ready response — clear, scoped, and aligned to the question being asked.
Feedback Loop
Every interaction improves the system:
Clarifies intent
Refines retrieval
Improves context rules
Strengthens trust over time
This loop is what allows the Knowledge OS to evolve without constant re-engineering.
Why This Is Not a Chatbot or Search Diagram
Search stops at retrieval.
Chatbots stop at conversation.
A Knowledge Operating System closes the loop — from knowledge to reasoning to learning.
That closed loop is what makes the system sustainable at scale.
Common Mistakes We See
Most RAG initiatives don’t fail because the technology is weak.
They fail because expectations and design choices drift early.
Here are some patterns we consistently see.
Starting with tools instead of questions
Teams often begin by selecting platforms, models, or vector databases.
Without clarity on what questions must be answered, the system grows wide but shallow.
Treating RAG like a one-time project
Knowledge changes continuously.
When RAG is built as a “deploy and forget” solution, answers slowly lose relevance and trust.
Skipping context design
This is one of the most expensive shortcuts.
Without context, answers may be technically correct but practically unusable.
Overloading the system with everything
More data does not mean better answers.
Uncurated knowledge creates noise and uncertainty.
Ignoring ownership and governance
When no one owns knowledge quality, trust erodes.
People stop relying on the system even if it works.
The teams that succeed treat RAG less like an AI experiment and more like organizational infrastructure.
What RAG Can and Cannot Do
RAG is powerful, but it is not magic.
Clarity about its boundaries is what keeps expectations realistic and adoption healthy.
What RAG Does Well
RAG excels at:
Connecting scattered knowledge into coherent answers
Applying context consistently
Reducing time spent searching and interpreting
Supporting decisions with traceable reasoning
It is especially effective when questions are:
Repeated across teams
Time-sensitive
Dependent on multiple knowledge sources
In these situations, RAG acts like a reliable thinking assistant, not a replacement for people.
What RAG Should Not Be Asked to Do
RAG is not suited for:
Making final judgments in ambiguous or ethical situations
Replacing domain experts
Operating without human oversight
Deciding strategy in isolation
When organizations push RAG beyond these boundaries, trust erodes quickly.
The most successful teams position RAG as:
“A system that improves the quality and speed of thinking — not the owner of decisions.”
That framing keeps humans firmly in control.
RAG Is Not Just AI Adoption. It’s a Shift in How Knowledge Works.
When organizations talk about RAG, the conversation often starts with models, embeddings, or tools.
But the real shift happens elsewhere.
RAG works best when it is treated as a knowledge operating layer — one that:
Brings the right knowledge forward
Applies context before reasoning
Supports decisions instead of overwhelming them
Seen this way, RAG is not about replacing people.
It is about removing friction from thinking.
Across organizations, the pattern is consistent:
Faster alignment
Better conversations
More confident decisions
Less time spent searching and reconciling
The teams that succeed don’t start by asking,
“What AI should we use?”
They start by asking,
“What should our organization be able to answer, reliably and repeatedly?”
Once that question is clear, the system almost designs itself.
A Simple Way to Think About Next Steps
If you are exploring RAG today, consider starting here:
Identify a few questions that truly matter
Decide which knowledge you trust
Design for context before intelligence
Treat learning and governance as part of the system
That mindset turns RAG from an experiment into infrastructure.
Final Recap
RAG is more than retrieval or chat
It behaves like a Knowledge Operating System
Value comes from orchestration, not automation
The goal is decision-ready knowledge, not answers alone
When knowledge flows well, organizations think better.
And when organizations think better, everything else follows.